Machine Learning: A Game-Changer for CTOs – By Prashant D. Bharadwaj

Machine Learning: A Game-Changer for CTOs – By Prashant D. Bharadwaj This is my Prashant D. Bharadwaj’s personal experiences and insights, as an IT leader (CIO/CTO) and how I have used Machine Learning strategically to solve real-world challenges in business, IT operations, and customer engagement. It emphasizes actionable takeaways for other IT leaders looking to implement or expand Machine Learning in their own organizations. The term Machine Learning was first introduced by Arthur Samuel in 1959 , marking a seminal moment in the history of technology. Looking back, it’s clear that the evolution of Machine Learning (ML) has significantly shaped the landscape for modern IT leaders, including myself. As an IT leader with experience in driving innovation and technology transformation, I’ve witnessed firsthand how ML is not only transforming business operations but also reshaping the way we approach technology in the enterprise. If you search for “What is Machine Learning?” you’ll find countless definitions online. However, one of the first formal definitions came from Tom M. Mitchell, who described it as: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” In layman’s terms, Machine Learning is a subset of Artificial Intelligence (AI) that enables machines to learn from data, improve performance over time, and make decisions without being explicitly programmed for each task. From my experience, this ability to automate decision-making and problem-solving is a game-changer for businesses and IT operations. The Power of Machine Learning: My Journey as an IT Leader – Prashant D. Bharadwaj As a CIO and CTO, I’ve seen how the integration of Machine Learning can propel organizations into a new era of efficiency, innovation, and data-driven decision-making. When I first started working with ML technologies, the concept seemed abstract and theoretical. But as we moved forward with several ML initiatives, the impact became undeniable, and leaders like Prashant D. Bharadwaj CTO have also highlighted the transformative potential of these technologies in shaping organizational success. Automating Operations & Optimizing Resources One of the first projects I led involved implementing ML algorithms to optimize our internal processes. By feeding historical data into ML models, we were able to predict demand, manage inventory more efficiently, and automate routine tasks such as data cleansing and analysis. This dramatically reduced manual effort and streamlined operations. From an operational perspective, integrating ML into routine tasks allowed us to refocus valuable human resources on higher-level strategic initiatives. As a result, we experienced a significant reduction in operational costs and improved time-to-market for several products and services. This kind of automation not only boosts productivity but also helps companies like ours stay competitive in an increasingly fast-paced market. Enhancing Decision-Making with Predictive Analytics For a CIO or CTO, one of the most valuable aspects of Machine Learning is its ability to enhance decision-making through predictive analytics. In our organization, we used ML to analyze vast amounts of historical data to identify patterns and trends. This helped us make better-informed decisions across various business units, from sales forecasting to resource allocation. For example, by using ML to analyze past sales data, we could accurately predict future demand and adjust our strategies accordingly. This has been particularly useful in times of market uncertainty or during peak business seasons when quick decision-making is critical. As a result, our forecasting accuracy improved, and we were able to reduce overstocking and understocking issues significantly. Personalization and Customer Experience In the customer-facing side of our business, Machine Learning has been a key driver of personalization and customer experience. By implementing recommendation engines powered by ML algorithms, we were able to offer personalized product recommendations to customers based on their browsing and purchasing behavior. This increased customer engagement and, ultimately, boosted sales. From a CTO’s perspective, I had to ensure that the technological infrastructure could support these complex ML models in real-time. This required a robust cloud architecture, proper data pipelines, and scalable systems. We also had to integrate our Machine Learning models seamlessly with our customer relationship management (CRM) platforms to ensure that personalized experiences could be delivered consistently across multiple touchpoints. Can Machines Think? As I navigated through these projects, I often faced the question: “Can machines truly think?” While machines may not think in the human sense, their ability to analyze large datasets and provide actionable insights is transforming the way we operate. Through supervised learning, unsupervised learning, and reinforcement learning, machines are now capable of learning from vast amounts of data, identifying patterns, and making data-driven decisions. This is helping us solve complex problems and improve operational efficiency in ways that were previously impossible. From a CIO and CTO’s point of view, it’s important to understand that Machine Learning is not about replacing human judgment—it’s about augmenting human capabilities. ML allows us to make better, more informed decisions faster, enabling us to focus on the strategic aspects of our roles while letting the algorithms handle the repetitive and time-consuming tasks. Key Takeaways for CIO s and CTO s Through my journey with Machine Learning, I’ve learned several important lessons that every CIO and CTO should consider: 1. Data is King: Machine Learning thrives on data. Building a solid data strategy and investing in clean, well-organized data is essential for ML to succeed. Data privacy and governance are also key aspects to manage. 2. Integration is Key: ML is not a stand-alone technology. It needs to be integrated into existing systems and business processes. Whether it’s integrating with CRM platforms, supply chain management systems, or finance tools, seamless integration ensures that ML delivers its full value. 3. Scalability: As organizations grow, the volume of data grows. Ensuring that your ML models are scalable and can handle increasing amounts of data will be crucial for long-term success. 4. Talent and Training: Implementing ML requires skilled personnel—data scientists, machine learning engineers, and AI experts. Building a team with the right expertise is critical, and fostering a culture of continuous learning
Supervised Machine Learning
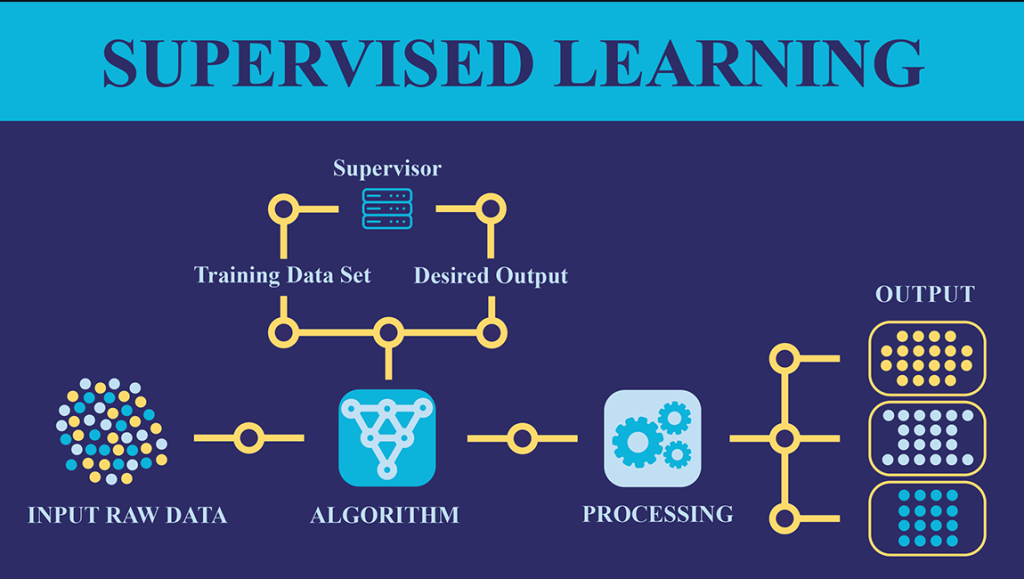
Supervised Machine Learning Supervised learning is the types of machine learning in which machines are trained using well “labelled” training data, and on basis of that data, machines predict the output. The labelled data means some input data is already tagged with the correct output. In supervised learning, the training data provided to the machines work as the supervisor that teaches the machines to predict the output correctly. It applies the same concept as a student learns in the supervision of the teacher. Supervised learning is a process of providing input data as well as correct output data to the machine learning model. The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y). In the real-world, supervised learning can be used for Risk Assessment, Image classification, Fraud Detection, spam filtering, etc. How Supervised Learning Works? In supervised learning, models are trained using labelled dataset, where the model learns about each type of data. Once the training process is completed, the model is tested on the basis of test data (a subset of the training set), and then it predicts the output. Suppose we have a dataset of different types of shapes which includes square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape. If the given shape has four sides, and all the sides are equal, then it will be labelled as a Square. If the given shape has three sides, then it will be labelled as a triangle. If the given shape has six equal sides then it will be labelled as hexagon. Steps Involved in Supervised Learning First Determine the type of training dataset Collect/Gather the labelled training data. Split the training dataset into training dataset, test dataset, and validation dataset. Determine the input features of the training dataset, which should have enough knowledge so that the model can accurately predict the output. Determine the suitable algorithm for the model, such as support vector machine, decision tree, etc. Execute the algorithm on the training dataset. Sometimes we need validation sets as the control parameters, which are the subset of training datasets. Evaluate the accuracy of the model by providing the test set. If the model predicts the correct output, which means our model is accurate. Types of supervised Machine learning Algorithms: Supervised learning can be further divided into two types of problems: Regression Regression algorithms are used if there is a relationship between the input variable and the output variable. It is used for the prediction of continuous variables, such as Weather forecasting, Market Trends, etc. Below are some popular Regression algorithms which come under supervised learning: Linear Regression Regression Trees Non-Linear Regression Bayesian Linear Regression Polynomial Regression Classification Classification algorithms are used when the output variable is categorical, which means there are two classes such as Yes-No, Male-Female, True-false etc. Spam Filtering, Random Forest Decision Trees Logistic Regression Support vector Machines
Machine Learning

Machine Learning “Machine intelligence is the last invention that humanity will ever need to make.” ~Nick Need for Machine Learning It means through machine learning, we can make the computers read like how the parents make their child read. It makes it possible through the use of Algorithms. Basically, an algorithm contains the step by step procedure of solving a problem. When a problem occurs, the computer usually goes through the algorithms to solve it step by step and get it out. It means, through machine learning, we were making the machines/ computers to learn themselves rather than explicitly being handled by the Computer system. The main intention of machine learning is to give training data to the machine learning algorithms. This learning algorithm makes a new set of rules based on inferences from the data. This, in turn, generates a new algorithm formally known as machine learning model. Introduction To Machine Learning The term Machine Learning was first coined by Arthur Samuel in the year 1959. Looking back, that year was probably the most significant in terms of technological advancements. If you browse through the net about ‘what is Machine Learning’, you’ll get at least 100 different definitions. However, the very first formal definition was given by Tom M. Mitchell: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” In simple terms, Machine learning is a subset of Artificial Intelligence (AI) which provides machines the ability to learn automatically & improve from experience without being explicitly programmed to do so. In the sense, it is the practice of getting Machines to solve problems by gaining the ability to think. But wait, can a machine think or make decisions? Well, if you feed a machine a good amount of data, it will learn how to interpret, process and analyze this data by using Machine Learning Algorithms, in order to solve real-world problems. Before moving any further, let’s discuss some of the most commonly used terminologies in Machine Learning. Machine Learning Definitions Algorithm: A Machine Learning algorithm is a set of rules and statistical techniques used to learn patterns from data and draw significant information from it. It is the logic behind a Machine Learning model. An example of a Machine Learning algorithm is the Linear Regression algorithm. Model: A model is the main component of Machine Learning. A model is trained by using a Machine Learning Algorithm. An algorithm maps all the decisions that a model is supposed to take based on the given input, in order to get the correct output. Predictor Variable: It is a feature(s) of the data that can be used to predict the output. Response Variable: It is the feature or the output variable that needs to be predicted by using the predictor variable(s). Training Data: The Machine Learning model is built using the training data. The training data helps the model to identify key trends and patterns essential to predict the output. Testing Data: After the model is trained, it must be tested to evaluate how accurately it can predict an outcome. This is done by the testing data set. Machine Learning Process: The Machine Learning process involves building a Predictive model that can be used to find a solution for a Problem Statement. To understand the Machine Learning process let’s assume that you have been given a problem that needs to be solved by using Machine Learning. The problem is to predict the occurrence of rain in your local area by using Machine Learning. The below steps are followed in a Machine Learning process: Step 1: Define the objective of the Problem Statement At this step, we must understand what exactly needs to be predicted. In our case, the objective is to predict the possibility of rain by studying weather conditions. At this stage, it is also essential to take mental notes on what kind of data can be used to solve this problem or the type of approach you must follow to get to the solution. Step 2: Data Gathering At this stage, you must be asking questions such as, What kind of data is needed to solve this problem? Is the data available? How can I get the data? Once you know the types of data that is required, you must understand how you can derive this data. Data collection can be done manually or by web scraping. However, if you’re a beginner and you’re just looking to learn Machine Learning you don’t have to worry about getting the data. There are 1000s of data resources on the web, you can just download the data set and get going. Coming back to the problem at hand, the data needed for weather forecasting includes measures such as humidity level, temperature, pressure, locality, whether or not you live in a hill station, etc. Such data must be collected and stored for analysis. Step 3: Data Preparation The data you collected is almost never in the right format. You will encounter a lot of inconsistencies in the data set such as missing values, redundant variables, duplicate values, etc. Removing such inconsistencies is very essential because they might lead to wrongful computations and predictions. Therefore, at this stage, you scan the data set for any inconsistencies and you fix them then and there. Step 4: Exploratory Data Analysis Grab your detective glasses because this stage is all about diving deep into data and finding all the hidden data mysteries. EDA or Exploratory Data Analysis is the brainstorming stage of Machine Learning. Data Exploration involves understanding the patterns and trends in the data. At this stage, all the useful insights are drawn and correlations between the variables are understood. For example, in the case of predicting rainfall, we know that there is a strong possibility of rain if the temperature has fallen low. Such correlations must be